
В данном разделе размещается ссылка на приложение мониторинга инфраструктурных узлов.
Мониторинг осуществляется при помощи взаимодействия следующих инструментов:
-
Telegraf – open source агент. Используется для сбора метрик и данных из системы
-
InfluxDB – свободно распространяемая TSDB база данных (time series database). Все данные, собранные Telegraf, передаются в InfluxDB
-
Grafana – инструмент по графическому отображению метрик, совместимый с базой данных InfluxDB. Предназначен для создания панелей индикаторов (дашбордов), отображающих определенные показатели в течение установленного периода времени
При первом переходе в раздел «Статистика» выполняется переход на страницу авторизации в Grafana.
Обратитесь к вашему Администратору, чтобы получить логин и пароль для входа в личный кабинет Grafana.
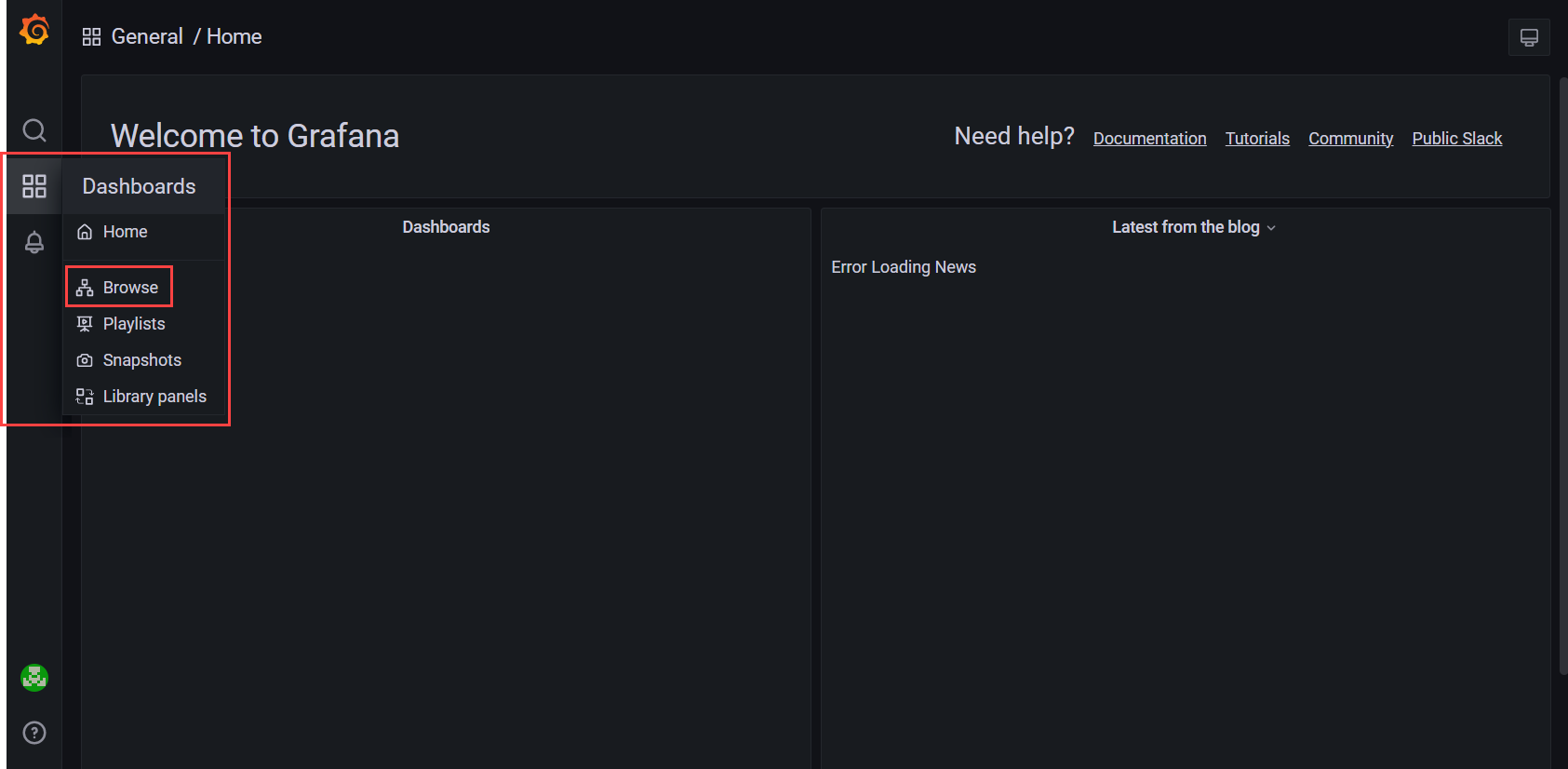
Для просмотра собираемых метрик выполните следующие действия:
-
Нажмите кнопку «Dashboards» для вызова меню
-
Выберите пункт «Browse» для перехода к списку панелей
-
Нажмите на название нужной панели
По умолчанию предлагается три набора дашбордов:
Мониторинг по инфраструктуре
Предназначен для мониторинга в рамках настраиваемых инфраструктурных единиц: областей, регионов, зданий, групп и т. п.
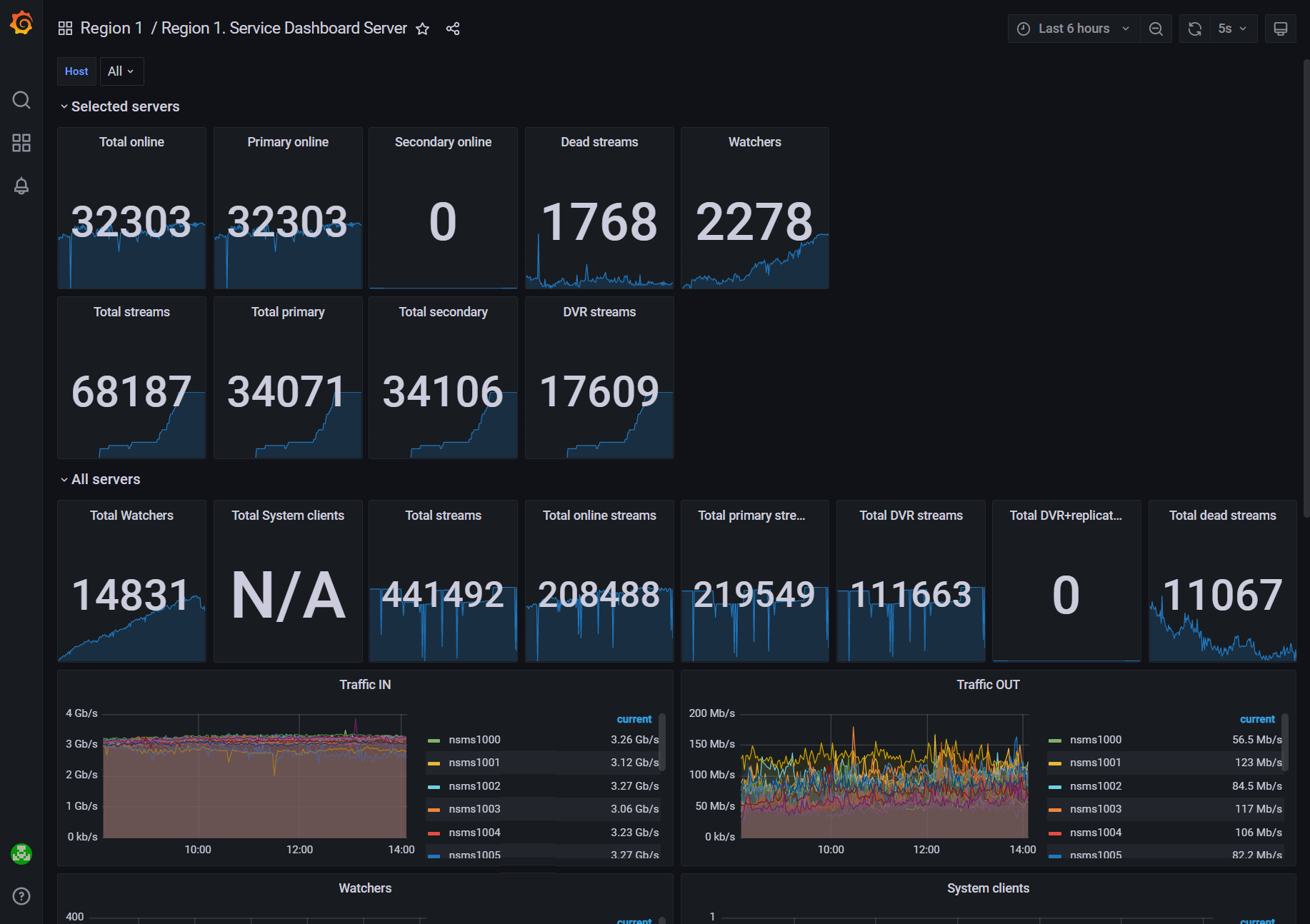
Набор включает следующие дашборды:
-
Server: region cluster – мониторинг параметров сервиса Mediaserver: версионность, загрузка процессора, памяти, статистика по сокетам
-
Common indicators – cтатистика по трафику на медиасерверах (общая и по каждому медиасерверу)
-
Service Dashboard Server – статистика по камерам, стримам, пользователям, трафику, просматривающим
-
3 days storage usage forecast – трехдневный прогноз заполняемости дисков
-
Disks health – мониторинг ошибок по дискам (HDD и SSD)
-
System dashboard: region cluster – мониторинг серверных метрик (память, процессы, сеть, диски и т. д.)
Alerts
Содержит дашборды мониторинга и Alert rules, настроенные на отклонение от допустимых показателей.
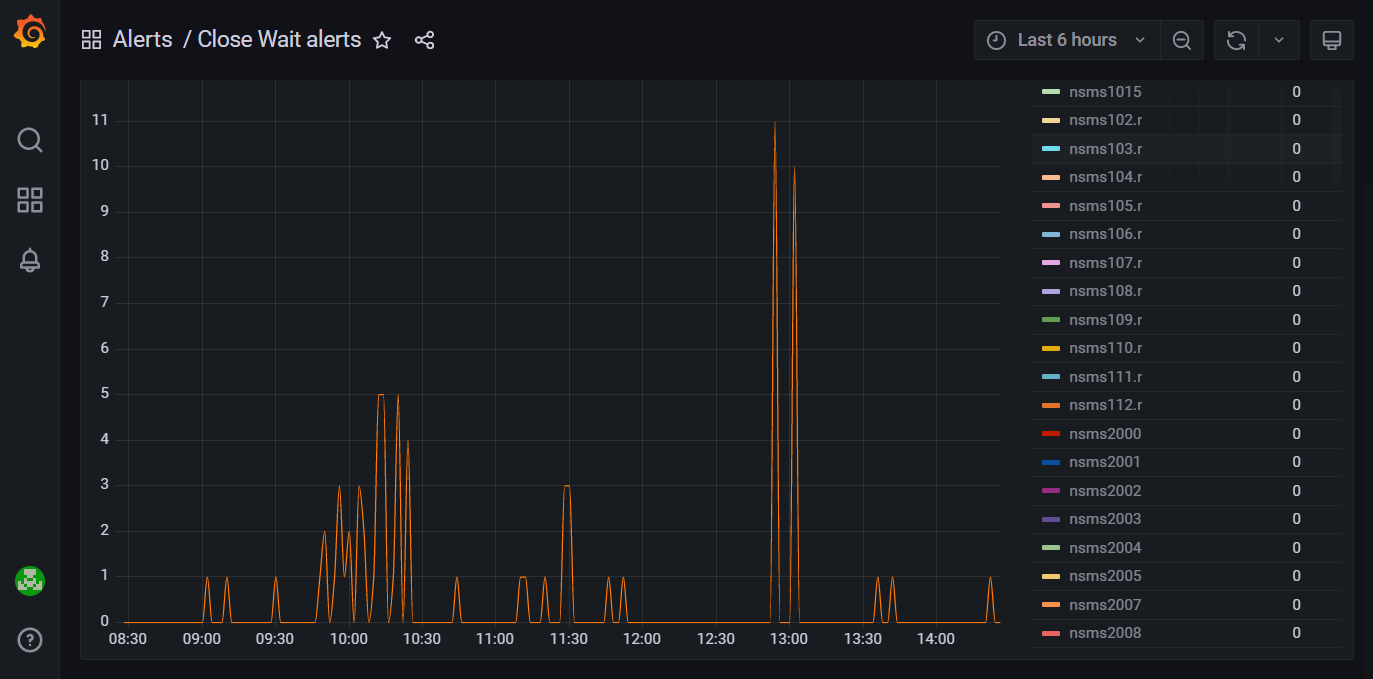
-
Close Wait alerts – мониторинг параметра close_wait для всех медиасерверов, а также алерты в случае превышения допустимого значения
-
Disk Usage alerting – мониторинг заполняемости дисков, а также алерты в случае превышения допустимого значения
-
Service state & input traffic – мониторинг входящего трафика на сервер, а также алерты в случае понижения ниже определенного значения
Monitoring
Содержит дашборды для мониторинга различных показателей работы и состояния сервисов на инсталяции Production.
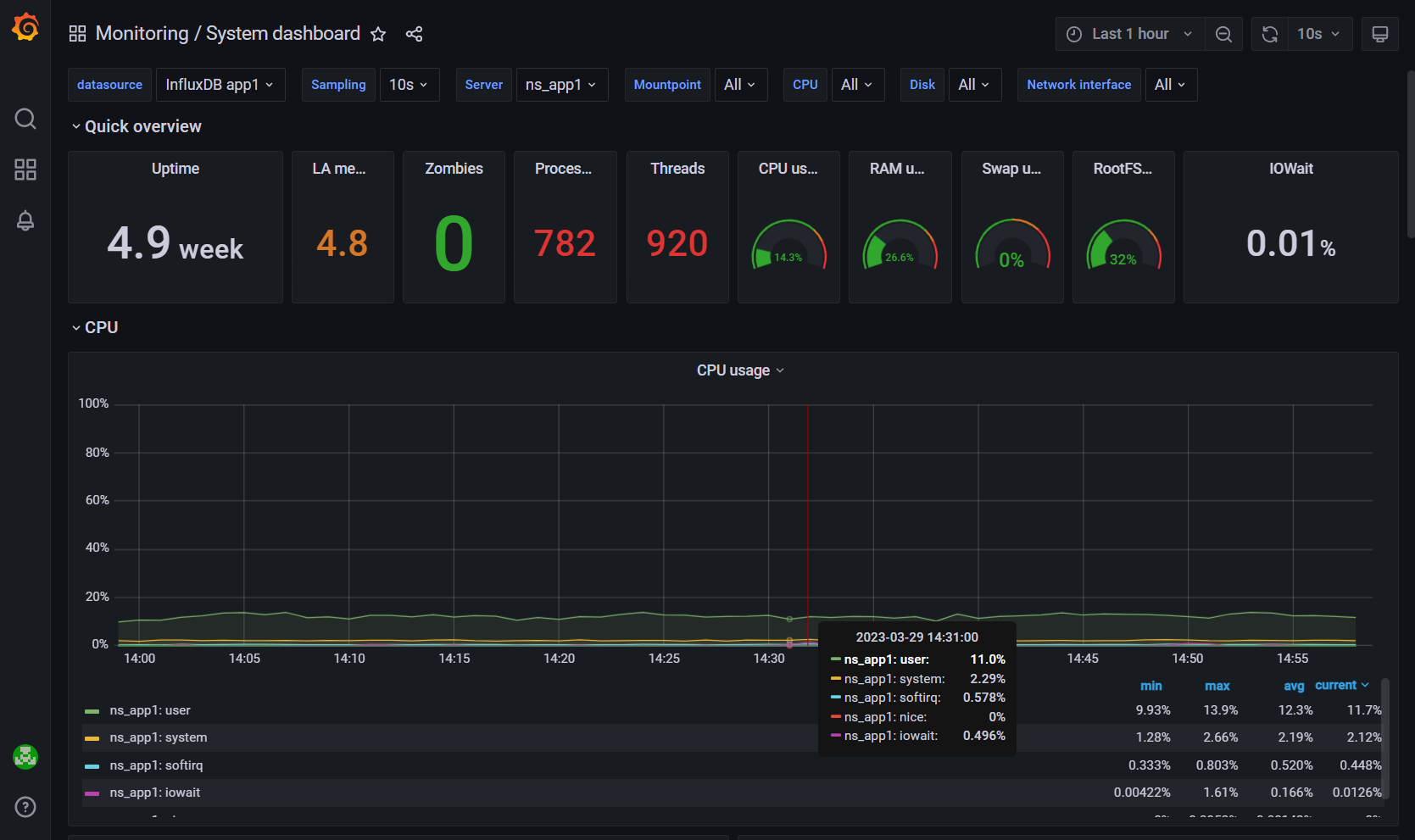
-
DHCP – мониторинг состояния сервиса DHCP и статистики его работы
-
NS_APP Monitoring – мониторинг загрузки процессора и памяти наиболее ресурсоемкими процессами
-
Percona cluster – мониторинг состсояния кластера percona (кластер из трех нод DB), а также алерты при недоступности отдельных нод
-
Supervisor processes monitoring – мониторинг состояния процессов, запущенных через supervisor на двух App-серверах
-
System dashboard – мониторинг серверных метрик (память, процессы, сеть, диски и т. д.)